Chi-Square Test med Excel
Chi-Square-test i excel er den mest almindelige ikke-parametriske test, der bruges til at sammenligne to eller flere variabler for tilfældigt valgte data. Det er en type test, der bruges til at finde ud af sammenhængen mellem to eller flere variabler, dette bruges i statistikker, der også er kendt som Chi-Square P-værdi, i Excel har vi ikke en indbygget funktion, men vi kan bruge formler til at udføre chi-kvadrat test i Excel ved hjælp af den matematiske formel til Chi-Square Test.
Typer
- Chi-Square test for god pasform
- Chi-Square test for uafhængighed af to variabler.
# 1 - Chi-Square test for god pasform
Det bruges til at opfatte nærheden af en prøve, der passer til en befolkning. Symbolet for Chi-Square-testen er (2). Det er summen af alt ( Observeret antal - Forventet antal) 2 / Forventet antal.
- Hvor k-1 frihedsgrader eller DF.
- Hvor Oi er den observerede frekvens, er k kategori, og Ei er den forventede frekvens.
Bemærk: - Tilpasning af en statistisk model henviser til forståelsen af, hvor godt stikprøvedata passer til et sæt observationer.
Anvendelser
- Låntagernes kreditværdighed baseret på deres aldersgrupper og personlige lån
- Forholdet mellem præstationen for sælgere og modtaget træning
- Afkast på en enkelt aktie og på aktier i en sektor som lægemidler eller bankvirksomhed
- Kategori af seere og virkningen af en tv-kampagne.
# 2 - Chi-Square test for uafhængighed af to variabler
Det bruges til at kontrollere, om variablerne er autonome over for hinanden eller ej. Med (r-1) (c-1) frihedsgrader
Hvor Oi er den observerede frekvens, r er antallet af rækker, c er antallet af kolonner, og Ei er den forventede frekvens
Bemærk: - To tilfældige variabler kaldes uafhængige, hvis sandsynlighedsfordelingen for den ene variabel ikke påvirkes af den anden.Anvendelser
Uafhængighedstest er velegnet til følgende situationer:
- Der er en kategorisk variabel.
- Der er to kategoriske variabler, og du bliver nødt til at bestemme forholdet mellem dem.
- Der er krydstabeller, og forholdet mellem to kategoriske variabler skal findes.
- Der er ikke-kvantificerbare variabler (for eksempel svar på spørgsmål som: vælger medarbejdere i forskellige aldersgrupper forskellige typer sundhedsplaner?)
Hvordan udføres Chi-Square-testen i Excel? (med eksempel)
Lederen af en restaurant ønsker at finde sammenhængen mellem kundetilfredshed og lønningerne til de mennesker, der venter på borde. I dette vil vi oprette hypotesen til at teste Chi-Square
- Hun tager en tilfældig prøve på 100 kunder, der spørger, om tjenesten var fremragende, god eller dårlig.
- Derefter kategoriserer hun lønningerne til de mennesker, der venter, som lave, mellemstore og høje.
- Antag, at niveauet af betydning er 0,05. Her angiver H0 og H1 uafhængighed og afhængighed af servicekvaliteten på lønningerne til folk, der venter på bordene.
- H 0 - servicekvalitet afhænger ikke af lønnen til folk, der venter på bordene.
- H 1 - servicekvalitet afhænger af lønningerne til folk, der venter på bordene.
- Hendes fund er vist i nedenstående tabel:
I dette har vi 9 datapunkter, vi har 3 grupper, som hver har en anden besked om løn, og resultatet er angivet nedenfor.

Nu skal vi tælle summen af alle rækker og kolonner. Vi gør dette ved hjælp af formlen, dvs. SUM. For at samle det fremragende i den samlede kolonne har vi skrevet = SUM (B4: D4) og derefter trykke på enter-tasten.

Dette vil give os 26 . Vi udfører det samme med alle rækker og kolonner.

For at beregne frihedsgraden (DF) bruger vi (r-1) (c-1)
DF = (3-1) (3-1) = 2 * 2 = 4
- Der er 3 kategorier af tjenester og 3 kategorier af løn.
- Vi har 27 respondenter med en medium løn (nederste række, midt)
- Vi har 51 respondenter med en god service (sidste kolonne, midten)
Nu skal vi beregne de forventede frekvenser: -
Forventede frekvenser kan beregnes ved hjælp af en formel: -
- For at beregne for det fremragende, bruger vi multiplikation af det samlede antal lav med det samlede antal fremragende divideret med N.
Antag, at vi skal beregne for 1. række og 1. kolonne (= B7 * E4 / B9 ) . Dette giver det forventede antal kunder, der har stemt Fremragende service til lønningerne til de mennesker, der venter så lave, dvs. 8,32 .
- E 11 = - (32 * 26) / 100 = 8,32 , E 12 = 7,02 , E 13 = 10,66
- E 21 = 16,32 , E 22 = 13,77 , E 23 = 20,91
- E 31 = 7,36 , E 32 = 6,21 , E 33 = 9,41
Tilsvarende skal vi gøre det samme for alle, og formlen anvendes i nedenstående diagram.

Vi får den forventede hyppighedstabel som angivet nedenfor: -

Bemærk: - Antag, at niveauet af betydning er 0,05. Her betegner H0 og H1 uafhængigheden og afhængigheden af servicekvaliteten af lønningerne til folk, der venter på bordene.
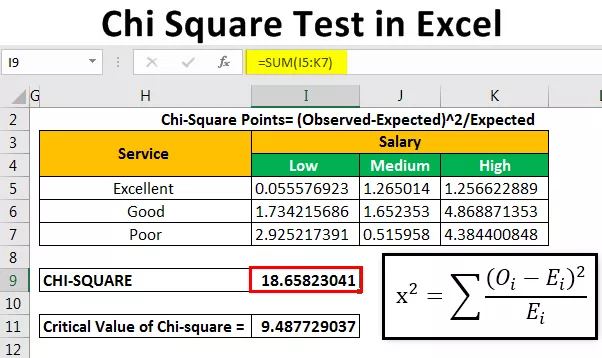
Efter beregning af den forventede frekvens beregner vi chi-kvadrat datapunkter ved hjælp af en formel.
Chi-Square-point = (observeret-forventet) 2 / forventet
For at beregne det første punkt skriver vi = (B4-B14) 2 / B14.

Vi kopierer og indsætter formlen i andre celler for automatisk at udfylde værdien.

Herefter beregner vi chi-værdien (beregnet værdi) ved at tilføje alle de værdier, der er angivet over tabellen.

Vi fik Chi-værdien som 18.65823 .

For at beregne den kritiske værdi for dette bruger vi en chi-kvadratisk kritisk værditabel, hvor vi kan bruge formlen nedenfor.
Denne formel indeholder 2 parametre CHISQ.INV.RT (sandsynlighed, grad af frihed).
Sandsynligheden er 0,05, og det er en væsentlig værdi, der hjælper os med at afgøre, om vi skal acceptere Null Hypothesis (H 0 ) eller ej.

Den kritiske værdi af chi-kvadrat er 9.487729037.

Nu finder vi værdien af chi-firkanten eller (P-værdi) = CHITEST (faktisk_ række, forventet række)
Område fra = CHITEST (B4: D6, B14: D16) .

Som vi har set, er værdien af chi-testen eller P-værdien = 0,00091723.

Vi har beregnet alle værdierne. De chi-square (Beregnet værdi) værdier er kun signifikant, når dens værdi er den samme eller mere end den kritiske værdi 9,48, dvs. kritisk værdi (tabelværdien) skal være højere end den 18.65 at acceptere nulhypotesen (H 0 ) .
Men her Beregnet værdi > Tabuleret værdi
X 2 (beregnet)> X 2 (tabuleret)
18,65> 9,48
I dette tilfælde vil vi afvise Null Hypotesen (H 0 ), og alternativ (H 1 ) vil blive accepteret.
- Vi kan også bruge P-værdi til at forudsige det samme, dvs. hvis P-værdi <= α (signifikant værdi 0,05), vil Null-hypotesen blive afvist.
- Hvis P-værdien> α , må du ikke afvise nulhypotesen .
Her P-værdi (0,0009172) < α (0,05), afvis H 0 , accepter H 1
Fra ovenstående eksempel konkluderer vi, at servicekvaliteten er afhængig af lønnen til de mennesker, der venter.
Ting at huske
- Overvejer firkanten af en standard normalvariat.
- Evaluerer, om frekvenser observeret i forskellige kategorier varierer betydeligt fra de forventede frekvenser under et specificeret sæt antagelser.
- Bestemmer, hvor godt en antaget fordeling passer til dataene.
- Bruger beredskabstabeller (i markedsundersøgelser kaldes disse tabeller krydsfaner).
- Det understøtter målinger på nominelt niveau.








